Overview
Concepts
-
Fault: a defect that causes an internal error
- e.g., hardware issue, bug, network glitch
- “the CAUSE”
-
Failure: the system’s inability to perform its service, causing errors / downtime for end users
- often resulting from an unhandled fault
- e.g., server crash, message loss, split brain
- “the EFFECT”
Why it matters
Distributed systems experience partial failures (some parts work, others don’t); The goal isn’t to prevent all faults, but to design systems that can continue functioning reliably (i.e. fault tolerance) even when individual parts fail, thus achieving high reliability.
Concepts
- Partial Failure: the defining challenge of distributed systems, where some components fail while others remain operational, making failure detection difficult
- Fault Tolerance: designing systems to detect, isolate, and recover from faults without significant disruption, ensuring continued service
- Resilience: the ability to withstand faults and prevent them from becoming system-wide failures
Types of Faults vs. Failures
Faults (Causes)
- Hardware Faults: Physical issues (e.g., disk crashes, power loss, CPU failure)
- Software Faults: Code bugs, memory leaks, race conditions, unhandled exceptions
- Network Faults: Packet loss, high latency, network partitions (timeouts)
- Byzantine Faults: Malicious or arbitrary behavior from a node (e.g., sending conflicting info)
Categorized by Duration
-
Transient: occur once then gone
- e.g., momentary network congestion, causing packet loss
- handling: retries, timeouts, exponential backoff
-
Intermittent: appear & disappear (irregularly)
- e.g., race condition
-
Permanent: persist indefinitely until faulty component is fixed
- e.g., corrupted disk
Failures (Effect, the Observable Outcome)
- Node Failure: A server stops responding
- Network Failure: Communication breaks down between nodes
- System Failure: The entire system halts or becomes unavailable
- Partial Failure: Some parts work, others don’t, creating complex, non-deterministic states
- Method Failure: A specific function/operation fails, returning wrong results or freezing
Classical Flow
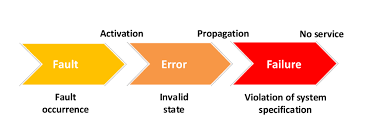
- Fault — Root cause (e.g., network cable unplugged)
- Error — Intermediate state (e.g., TCP connection timeout)
- Failure — Observable impact (e.g., service returns 503 to user)
Key Takeaways
- Distributed systems will fail; our goal is to anticipate faults, tolerate them, and fail gracefully
- Fault tolerance ensures continuity (e.g., replication, failover mechanisms)
- Fail-safe mechanisms ensure the system degrades gracefully instead of breaking